
はじめに #
日本語処理は「基礎知識さえあれば大丈夫」と思っていませんか?実は、それが落とし穴です。
このプロジェクトで経験したメール本文のキーワード置き換え不具合は、UTF-8/Shift-JIS の基礎知識では解決しませんでした。Heredoc 構文、データベースとの不整合、さらにはローカルとサーバーの環境差異が複合して、「症状は同じだが原因が異なる」という複雑な状況に陥ったのです。
本記事では、基礎知識から実装上の落とし穴、そして環境差異による複合問題まで、実装経験に基づいて解説します。
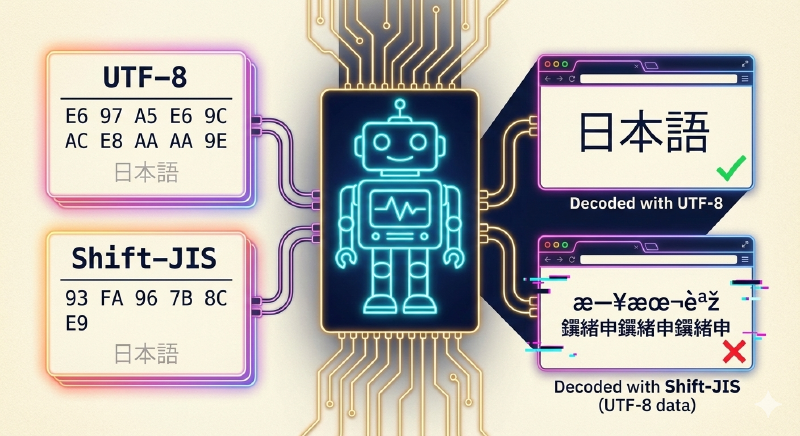
1. 基礎知識:UTF-8 と Shift-JIS の違い #
なぜエンコーディングを理解する必要があるのか #
日本語1文字のバイト数は、使用するエンコーディングによって異なります。これが、後々の問題の根本原因になることがあります。
UTF-8 vs Shift-JIS #
UTF-8
- 日本語1文字 = 3バイト
- 世界的標準、Web では主流
- 処理が複雑(可変長エンコーディング)
- 実は、あなたのスマートフォンで毎日使う絵文字😄も UTF-8 で表現されています。世界中のあらゆる言語や記号に対応できるのが、UTF-8 の大きな強みです。
Shift-JIS
- 日本語1文字 = 2バイト
- 日本語環境では以前主流
- レガシーシステムで残存
- 昔からある、(^^)はこちらの親戚表現です。
BOM(Byte Order Mark)
- ファイルの先頭に付加される識別子
- UTF-8 BOM vs UTF-8 (BOM なし) で挙動が異なる場合がある
- Windows / Mac / Linux で扱いが異なる
参考リンク #
- さよならシフトJIS、主なしとて春な忘れそ - PC Watch シフトJISの歴史、Windows メモ帳のUTF-8デフォルト化、BOM について詳しく解説。 エンコーディング移行の背景を理解する上で参考になります。
実装例から学ぶ:IGES レイヤー処理 #
異なる CAD ソフト間でのデータ交換時に、レイヤー名が日本語の場合、受け取り側で文字化けが発生しました。
送信側:UTF-8 でレイヤー名「配線」を送信
受信側:Shift-JIS で解釈しようとする
結果:文字化けして表示
原因を特定できたのは、UTF-8 では1文字3バイト、Shift-JIS では1文字2バイトという基礎知識があったから。これで問題が迅速に解決し、他のプロジェクト進行もスムーズになりました。
学び: 一見「小粒」な知識が、他分野(CAD ファイル処理)の課題解決に直結する。
2. 実装パターン集:PHP での日本語文字処理 #
文字列操作関数の落とし穴 #
PHP で日本語を扱う際、単純な strlen() や str_replace() を使うと、エンコーディングを正しく処理できません。
危険な例:
$text = "配線";
echo strlen($text); // 6(バイト数)
echo mb_strlen($text); // 2(文字数)
strlen() はバイト数を返すため、UTF-8 では日本語1文字 = 3バイトと計算されます。
推奨パターン #
パターン1:安全な文字列長の取得
// 文字数を正確に取得
$length = mb_strlen($text, 'UTF-8');
パターン2:安全な部分文字列抽出
// 指定位置から N 文字を抽出
$substring = mb_substr($text, 0, 5, 'UTF-8');
パターン3:確実なキーワード置き換え
// キーワード置き換え時はエンコード指定必須
mb_internal_encoding('UTF-8');
$result = str_replace($keyword, $replacement, $text);
3. 実装上の課題:Heredoc での置き換え不具合 #
問題現象 #
メール本文のキーワード置き換え処理で、Heredoc 構文内の日本語キーワードが置き換わりませんでした。
$mail_body = <<<EOT
お疲れ様です、【顧客名】さん
今回の【商品】についてのお問い合わせありがとうございます。
EOT;
$result = str_replace('【顧客名】', $customer_name, $mail_body);
// → 置き換わらない!
原因候補 #
-
Heredoc 内のエンコード指定不十分
- Heredoc 内で日本語が正しくエンコードされていない
-
データベースとのエンコード不整合
- DB から取得した値のエンコーディングが異なる
-
mb_*関数の仕様不理解- mb_strlen() など、デフォルト設定では環境依存
解決パターン #
// ステップ1:エンコーディング確認
mb_internal_encoding('UTF-8');
mb_http_output('UTF-8');
// ステップ2:DB 接続時も UTF-8 指定
$pdo = new PDO('mysql:host=...;charset=utf8mb4');
// ステップ3:安全な置き換え
$result = str_replace($keyword, $replacement, $mail_body);
4. 環境差異による複合問題(重要) #
実は、この問題の根本原因は、単一の日本語処理ではなく、複数の環境設定が重なった複合問題でした。
ローカルとサーバーの設定差異 #
| 項目 | ローカル | サーバー | 影響 |
|---|---|---|---|
| PHP バージョン | 7.3 | 8.4 | 文字関数の動作が異なる可能性 |
| 日本語設定 | なし | UTF-8 設定 | エンコーディング処理が環境依存 |
| ファイルアップロード上限 | 4MB | 2MB | エラー原因の判別困難 |
| エラー表示設定 | 遅延 | 即座 | デバッグ情報取得のタイミング異なる |
複合要因で起きたこと #
複数の問題が同じ症状を引き起こします:
- ファイル名が長い → エラー
- ファイルサイズが大きい → エラー
- 日本語の文字化け → エラー
結果:「症状は同じだが原因が異なる」という複雑性が生まれました。
実装時のチェックリスト #
- Heredoc/Nowdoc 内のエンコード指定を確認
- データベース接続のエンコード指定(charset=utf8mb4)
- PHP.ini での default_charset 設定を確認
- mb_internal_encoding() を明示的に設定
- ローカルとサーバーの PHP バージョン確認
- エラーログの詳細度設定を確認
5. 応用例と次のステップ #
IGES ファイル処理での活用 #
CAD レイヤー名の文字化け問題は、UTF-8/Shift-JIS の理解で迅速に解決できました。この知識は以下の場面でも活躍します:
- CSV ファイルの入出力
- 他システムとのデータ連携
- ファイル名の文字化け対策
動的文字列処理への応用 #
キーワード置き換え以外にも、以下の処理で同じ注意が必要です:
- メール本文生成
- PDF 内容の日本語処理
- ログファイルの文字化け対策
環境差異を吸収する実装パターン #
// アプリケーション起動時に必ず実行
function initialize_encoding() {
mb_internal_encoding('UTF-8');
mb_http_output('UTF-8');
ini_set('default_charset', 'UTF-8');
}
おわりに #
日本語処理の基礎知識は重要ですが、実装レベルでは以下が欠かせません:
- 基礎知識だけでなく、環境設定の理解
- ローカルとサーバーの差異への対策
- 複合要因による問題特定の難しさへの備え
このプロジェクトで経験した「症状は同じだが原因が異なる」という複雑な問題は、次のプロジェクトでの予防に役立つ貴重な教訓になりました。